1. 데이터의 구성 요소
1) 특징 (Feature, 독립변수 X):
데이터의 개별적인 측정 가능한 속성을 말합니다.
예를 들어, 스팸 메일을 분류할 때 '특정 단어의 빈도'나 '발신지'가 특징이 됩니다.
- 기계학습: 인간이 도메인 지식을 바탕으로 어떤 특징이 중요한지 직접 골라주어야 합니다 (Feature Engineering).
- 딥러닝: 데이터로부터 기계가 스스로 유용한 특징을 추출하여 학습합니다.
2) 레이블 (Label, 종속변수 Y):
우리가 예측하고자 하는 '정답'입니다.
개와 고양이 사진을 분류한다면 '개' 또는 '고양이'라는 이름표가 레이블이 됩니다.
기계학습에서 데이터들은 단순히 데이터가 많다고 좋은 것이 아니라, '정답(레이블)과 얼마나 의미 있는 상관관계를 갖는가'가 핵심
2. 학습과 모델링
- 학습 (Training): 입력 데이터(X)와 정답(Y) 사이의 관계를 가장 잘 설명하는 함수(f)나 수식을 찾아내는 과정입니다.
수학적으로는 오차를 최소화하는 가중치(Weight)를 찾는 과정이라고 할 수 있습니다. - 모델 (Model): 학습을 통해 만들어진 결과물입니다. 새로운 데이터를 넣었을 때 결과를 내놓는 '판단 규칙의 집합'입니다.
3. 예측과 평가
- 일반화 (Generalization): 학습에 사용되지 않은 새로운 데이터(Unseen Data)에 대해 모델이 얼마나 정확하게 예측하는지를 나타내는 능력입니다. 기계학습의 궁극적인 목표는 단순히 외우는 것이 아니라, 이 일반화 성능을 높이는 데 있습니다.
- 추론 (Inference): 학습이 완료된 모델에 새로운 데이터를 입력하여 결과값(예측치)을 얻어내는 실제 실행 과정을 의미합니다.
4. 학습 시 주의해야 할 상태
학습 과정에서는 일반화를 방해하는 두 가지 극단적인 상황을 경계해야 합니다.
- 과적합 (Overfitting):
모델이 학습 데이터에만 너무 과하게 최적화되어, 실제 새로운 데이터에서는 엉뚱한 답을 내놓는 상태입니다.
(수학 문제를 이해하지 않고 문제 번호와 답만 외운 상태와 같습니다.) - 과소적합 (Underfitting):
학습 데이터조차 제대로 익히지 못해 규칙을 찾지 못한 상태입니다. (공부량이 부족한 상태입니다.)
이 시각화는 통계 모델이 알려진 관측치 집합에 얼마나 잘 맞는지를 보여주며, 과소적합, 최적, 과대적합의 세 가지 결과를 나타냅니다. 통계 모델은 실제 데이터를 수학적으로 표현한 것으로, 데이터를 이해하고 예측하는 데 도움을 줍니다. 이 세 가지 개념은 머신러닝에서 매우 중요한데, 모델의 훈련 데이터와 미지의 데이터에 대한 성능과 관련이 있기 때문입니다.
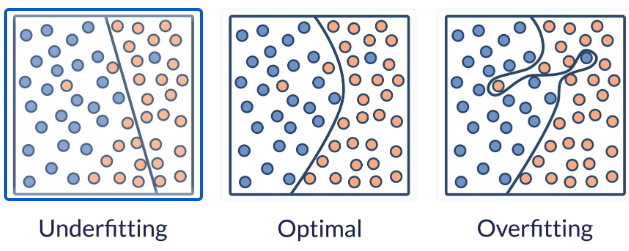
첫 번째 차트(underfitting)는 데이터에 과소적합된 모델을 보여줍니다. 직선 형태의 이 모델은 데이터를 선형적으로 분리 가능한 것처럼 취급하여 데이터의 근본적인 추세를 포착하지 못합니다. 이러한 단순함 때문에 모델이 훈련 데이터의 패턴을 충분히 학습하지 못하여 훈련 데이터와 새로운 미지의 데이터 모두에서 높은 오류율을 초래합니다.
두 번째 차트(optimal )는 최적의 모델을 보여줍니다. 차트의 선은 두 데이터 클래스를 정확하게 구분합니다. 이 모델은 훈련 데이터로부터 좋은 일반화 성능을 보여주며, 균형 잡힌 성능을 나타냅니다. 이는 모델이 노이즈에 과도하게 영향을 받지 않고 기본적인 패턴을 학습했기 때문에 새롭고 이전에 보지 못한 데이터에서도 좋은 성능을 보일 가능성이 높다는 것을 의미합니다.
마지막 차트(overfitting)는 과적합된 모델을 보여줍니다. 이 모델은 지나치게 복잡하고 훈련 데이터에 너무 가깝게 맞춰져 있습니다. 모델이 너무 유연해서 기본적인 패턴뿐만 아니라 훈련 데이터의 노이즈까지 학습하게 되는데, 이는 몇몇 데이터 포인트 주변에서 불규칙적인 동작을 보이는 데서 확인할 수 있습니다. 결과적으로, 이 모델은 훈련 데이터에서는 좋은 성능을 보이지만, 새롭고 이전에 접하지 못한 데이터에서는 성능이 저하될 가능성이 높습니다.
'업무 자동화 > AI' 카테고리의 다른 글
| 기계학습 용어들 - 상관관계 (0) | 2026.03.26 |
|---|---|
| 기계학습 (머신러닝(Machine Learning)) 개념 (0) | 2026.03.26 |
| 자동차 연비를 예측 하는 프로그램 #1 (0) | 2026.03.15 |
| 머신러닝의 작동 원리 (0) | 2026.03.11 |
| 회귀 분석(Regression Analysis) 이란? (0) | 2026.03.11 |



