반응형
■ 기계학습 정의
기존의 컴퓨터 프로그래밍이 사람이 정해준 규칙(If-Then)에 따라 움직였다면, 머신러닝은 컴퓨터가 데이터를 통해 스스로 학습하여 패턴을 찾아내고 미래를 예측하는 기술을 말합니다.
*기계지능 (Machine Intelligence)
전통적인 의미에서의 기계지능은 주로 규칙 기반(Rule-based) 시스템을 의미합니다.
1. 특징: 사람이 모든 경우의 수를 생각하여 If-Then 형태의 조건문으로 컴퓨터에게 명령을 내립니다.
2. 한계: 질문자가 제시하신 것처럼 사전에 등록되지 않은 미지의 질문이나 상황이 발생하면 컴퓨터는
판단 근거가 없어 대응이 불가능합니다.
3. 예시: 간단한 챗봇이나 초기 체스 프로그램 (정해진 길로만 움직임)
기계학습 (머신러닝(Machine Learning))은 데이터 속에서 스스로 규칙을 찾아내는 방식입니다.
- 특징:
수많은 데이터를 입력하면 컴퓨터가 통계적인 기법을 사용하여 데이터 간의 관계를 하나의 수식(모델)으로 만들어냅니다. - 장점:
명시적인 가이드라인이 없어도 새로운 데이터가 들어왔을 때 기존에 학습한 수식을 바탕으로 스스로 결과를 유추합니다. - 수식의 역할:
y = f(x) 라는 구조에서 데이터 x를 넣었을 때 최적의 정답 y를 내놓기 위해 함수 f()를 찾아가는 과정이 곧 학습입니다.
■ 인공지능과의 관계
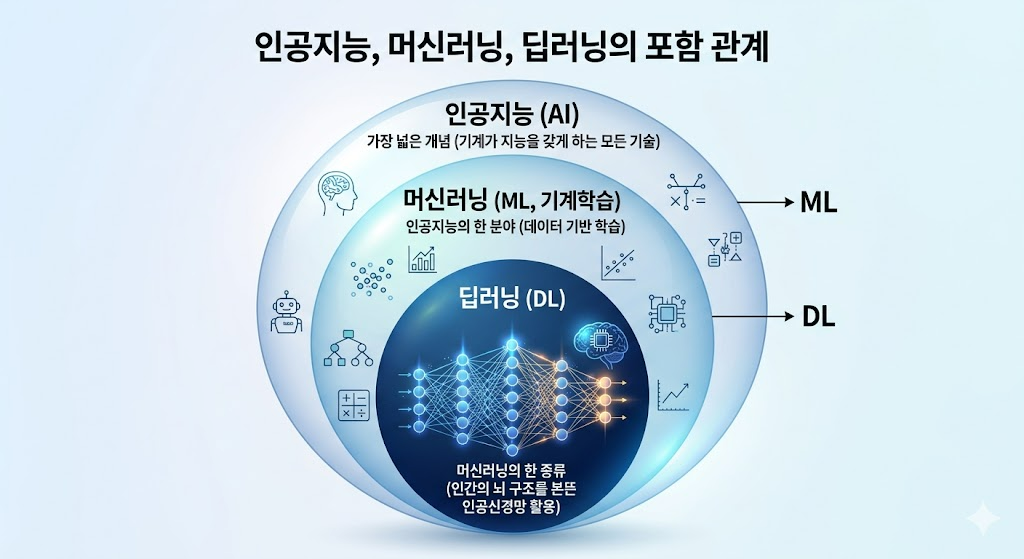
흔히 혼용되지만, 엄밀히 따지면 포함 관계가 존재합니다.
- 인공지능(AI): 가장 넓은 개념 (기계가 지능을 갖게 하는 모든 기술)
- 머신러닝(기계학습): 인공지능의 한 분야 (데이터 기반 학습)
- 딥러닝(Deep Learning): 머신러닝의 한 종류 (인간의 뇌 구조를 본뜬 인공신경망 활용)
■ 기계학습과 목적
데이터에서규칙을 찾아내어 수식으로 표현하는 모델(알고리즘, 함수)을 추출하는 것 입니다. [데이터 입력 → 파라미터 추정(학습) → 오차 계산 및 확인(검증)]의 흐름을 통해 최적의 수식(모델)을 만들어가는 과정입니다.
1. 학습 과정 (Training Process)
모델이 데이터의 특성을 파악하여 규칙을 정립하는 단계입니다.
- 방법: 샘플 데이터를 사용하여 입력(Input)과 출력(Output) 간의 관계를 분석합니다.
- 결과: 데이터의 특징을 가장 잘 나타내는 파라미터(매개변수)의 추정값을 찾아냅니다.
* 엑셀 구성 요소와 기계학습의 매칭 (파라미터(매개변수)란?)
예시 데이타
| 번호 | 세대주 이름 | 면적 | 층수 | 세대주구성 | 화장실 수 | 호 수 |
| 1 | 홍길동 | 25 | 3 | 2 | 1 | 301 |
| 2 | 김말자 | 104 | 12 | 5 | 2 | 1201 |
| 엑셀의 요소 | 기계학습에서의 의미 |
예시 (아파트 가격 예측)
|
| 행 (Row) | 데이터 샘플 (Sample) |
아파트 1채의 정보 (101동 1호)
|
| 열 (Column) | 특징 (Feature, x) |
면적, 층수, 준공 연도
|
| 파라미터 (Parameter) | 가중치 (Weight, w) |
면적이 가격에 미치는 영향력(수치)
|
기계학습의 목표는 y = ax + b라는 수식을 찾는 것과 같습니다. 여기서 파라미터는 바로 a와 b입니다.
- x (입력값): 엑셀의 각 열에 들어있는 값 (예: 면적 84m^2)
- y (출력값): 우리가 알고 싶은 결과 (예: 매매가 10억)
- 파라미터 (a, b): 면적(x)에 얼마를 곱해야(a) 실제 가격(y)과 비슷해지는지를 나타내는 고정된 값입니다.
엑셀 시트에 1,000개의 아파트 거래 기록(1,000개의 행)이 있다고 가정해 보겠습니다.
- 기계학습은 이 1,000개의 행을 모두 분석해서,
- "보통 면적에 1,200만 원(a)을 곱하고 5,000만 원(b)을 더하면 가격이 나오네!"라는 단 하나의 규칙(a, b)**을 찾아내는 과정입니다.
- 이때 찾은 1,200만 원과 5,000만 원이 바로 파라미터의 추정값입니다.
2. 검증 과정 (Validation Process)
학습된 모델이 얼마나 정확한지 성능을 확인하는 단계입니다.
- 방법: 학습에 사용하지 않은 새로운 데이터(미사용 데이터)를 모델에 대입합니다.
- 비교: 모델이 내놓은 추정 결과값과 실제 데이터의 실제 출력값을 대조합니다.
- 평가: 두 값의 차이를 바탕으로 오차율을 계산하여 모델의 신뢰도를 평가합니다.
반응형
'업무 자동화 > AI' 카테고리의 다른 글
| 기계학습 용어들 - 상관관계 (0) | 2026.03.26 |
|---|---|
| 기계학습 용어들 (0) | 2026.03.26 |
| 자동차 연비를 예측 하는 프로그램 #1 (0) | 2026.03.15 |
| 머신러닝의 작동 원리 (0) | 2026.03.11 |
| 회귀 분석(Regression Analysis) 이란? (0) | 2026.03.11 |



