데이터를 학습 하여 아파트 가격을 예측 하는 프로그램 만들기
1. 인간의 지식과 경험:
사람들은 "보통 집이 넓을수록, 지은 지 얼마 안 될수록 가격이 비싸다"라는 경험적 지식을 가지고 있습니다.
2. 데이터를 학습:
실제로 거래된 수만 건의 아파트 평수, 연식, 가격 데이터를 컴퓨터(엑셀이나 머신러닝 모델)에 입력합니다.
3. 스스로 패턴을 찾음:
회귀 분석 알고리즘이 데이터를 훑으며 "평수가 1평 늘어날 때마다 가격은 평균 5,000만 원씩 오르는구나"라는 수학적 공식($y = ax + b$)을 찾아냅니다. 이것이 바로 '패턴'입니다.
4. 새로운 지식 창출 및 예측하는 통찰 제공:
이제 한 번도 거래된 적 없는 새로운 아파트 정보(평수)를 넣으면, 모델이 "이 집은 약 12억 원 정도 할 것입니다"라고 예측 값을 내놓습니다. 이것이 우리가 얻는 통찰입니다.

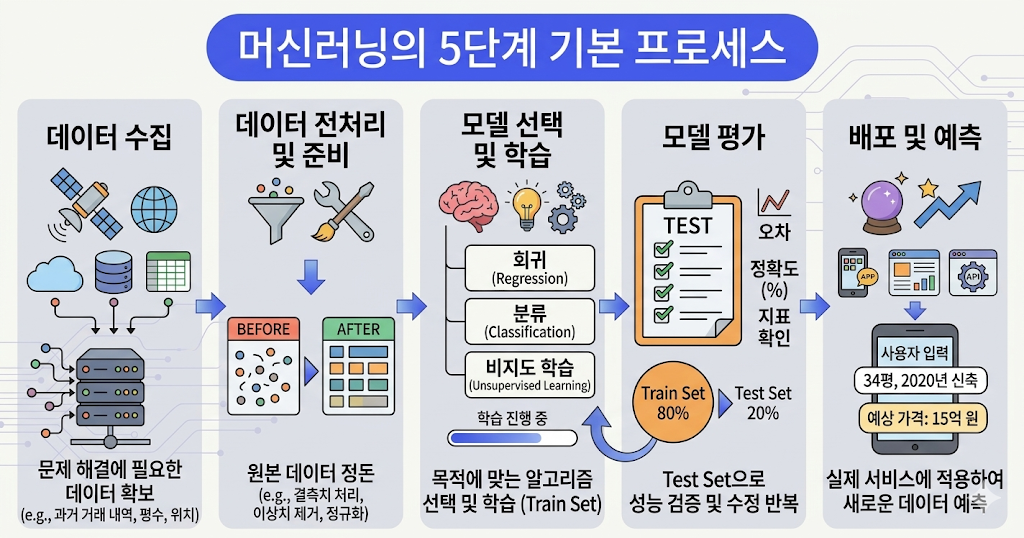
■ 머신러닝의 5단계 기본 프로세스
1. 데이터 수집 (Data Collection)
머신러닝의 가장 첫 단계이자 가장 중요한 단계입니다. 문제 해결에 필요한 데이터를 모으는 과정입니다.
- 예: 아파트 가격 예측을 위해 공공데이터 포털에서 과거 거래 내역, 평수, 위치, 건축 연도 등의 데이터를 가져옵니다.
2. 데이터 전처리 및 준비 (Data Preparation)
수집된 원본 데이터는 바로 사용할 수 없는 경우가 많습니다. "쓰레기를 넣으면 쓰레기가 나온다(Garbage In, Garbage Out)"는 말처럼 이 단계가 모델의 성능을 결정합니다.
- 결측치 처리: 비어있는 데이터 채우기
- 이상치 제거: 말도 안 되게 높거나 낮은 튀는 값 정리
- 데이터 정규화: 서로 다른 단위(평수와 가격 등)를 일정한 범위로 맞추기
3. 모델 선택 및 학습 (Model Selection & Training)
데이터의 특성에 맞는 알고리즘을 고르고, 데이터를 컴퓨터에 학습시켜 "패턴(공식)"을 찾게 하는 단계입니다.
- 모델 선택: 회귀(수치 예측), 분류(A/B 판별) 등 목적에 맞는 알고리즘 선택
- 학습: 전체 데이터 중 일부(Train Set)를 사용해 컴퓨터가 스스로 규칙을 찾도록 함
4. 모델 평가 (Evaluation)
학습에 사용하지 않은 나머지 데이터(Test Set)를 넣어 모델이 얼마나 정확하게 맞히는지 확인합니다.
- 지표 확인: 오차가 얼마나 적은지, 정확도는 몇 %인지 체크합니다. 만약 성적이 좋지 않다면 다시 2번이나 3번 단계로 돌아가서 수정합니다.
5. 배포 및 예측 (Deployment & Prediction)
검증이 완료된 모델을 실제 서비스에 적용하여 새로운 데이터를 입력받고 결과를 내놓는 단계입니다.
- 예: 사용자가 "34평, 2020년 신축"이라고 입력하면 모델이 "예상 가격은 15억 원입니다"라고 답을 줍니다.
🔄 프로세스는 끊임없이 반복됩니다
머신러닝 프로세스는 한 번으로 끝나지 않습니다. 시간이 지나 새로운 데이터가 쌓이면 모델은 다시 학습(Retraining)하여 더 똑똑해져야 합니다.
'업무 자동화 > AI' 카테고리의 다른 글
| 기계학습 (머신러닝(Machine Learning)) 개념 (0) | 2026.03.26 |
|---|---|
| 자동차 연비를 예측 하는 프로그램 #1 (0) | 2026.03.15 |
| 회귀 분석(Regression Analysis) 이란? (0) | 2026.03.11 |
| 데이터 표준화, 정규화 의미 (0) | 2026.03.08 |
| 컴퓨터가 이해 할 수 있도록, 데이터를 변환이 필요하다. #2 (0) | 2026.03.08 |



